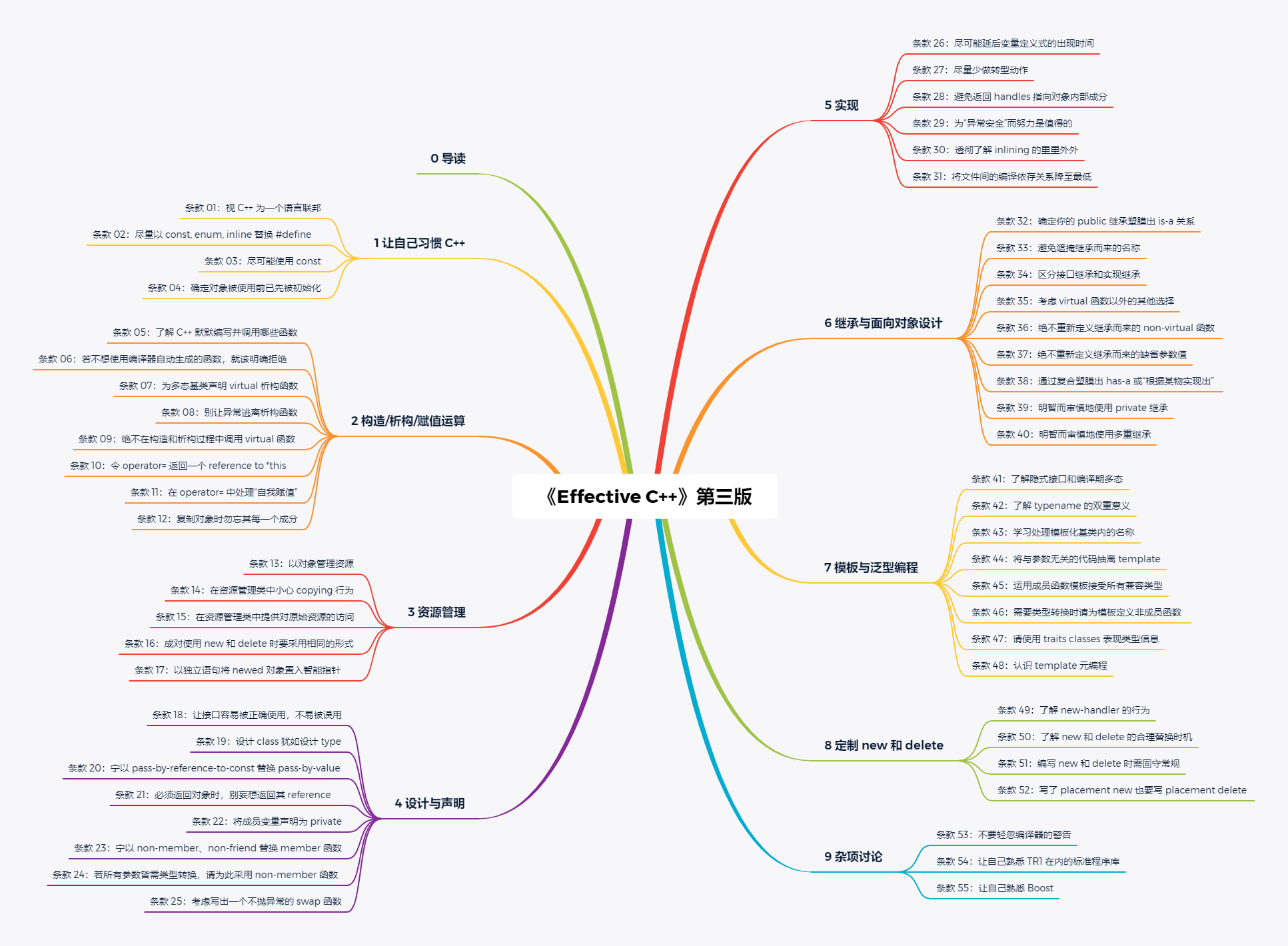
目录
0 导读
定义式是编译器为此对象分配内存的地点。
所谓
default构造函数,即缺省构造函数(也称默认构造函数),是一个可被调用而不带任何实参的构造函数,这样的构造函数要不没有参数,要不就是每个参数都有缺省值。explicit可以阻止类的构造函数被用来执行隐式类型转换(implicit type conversions),但被explicit关键字修饰的构造函数仍可被用来进行显示类型转换(explicit type conversions)。例如下面这个例子:1
2
3
4
5
6
7
8
9
10class B
{
public:
explicit B(int x = 0, bool b = true); // default 构造函数
};
void doSomething(B bObject); // 函数接受一个类型为 B 的对象
doSomething(28); // 错误,28 不能被隐式转换为 B 类型的对象
doSomething(B(28)); // 正确,使用 B 的构造函数将 28 显示转换为一个 B 类型的对象被声明为
explicit的构造函数禁止编译器执行非预期(往往也不被期望)的类型转换,构造函数应尽量使用explicit进行修饰,除非你真的希望允许构造函数被用于隐式类型转换。拷贝构造函数被用来“以同类型对象初始化自我对象”,拷贝赋值操作符(即
=)被用来“从另一个同型对象中拷贝其值到自我对象”。观察下面的示例:1
2
3
4
5
6
7
8
9
10
11class Widget
{
public:
Widget(); // default 构造函数
Widget(const Widget &rhs); // 拷贝构造函数
Widget &operator=(const Widget &rhs); // 拷贝赋值运算符
};
Widget w1(); // 调用 default 构造函数
Widget w2(w1); // 调用拷贝构造函数
w1 = w2; // 调用拷贝赋值运算符=也可以用来调用拷贝构造函数,例如下面的语句中,w3是新定义的对象,此时会调用Widget的拷贝构造函数:1
Widget w3 = w2;
以传值的形式向函数中传递用户自定义类型是个不好的习惯,因为函数内部会创建匿名对象,造成资源消耗,通常情况下应该是传引用,如果传入参数不会被改变,引用还应指定为
const的。对
null指针解引用会造成未定义行为:1
2int *p = 0; // p 是个 null 指针
std::cout << *p;char数组:1
char name[] = "Darla"; // name 是个 char 数组,大小为 6(字符串常量末尾还有有个结束符)
1 让自己习惯 C++
条款 01:视 C++ 为一个语言联邦
C++ 核心就是以下四点:
- C:C++ 以 C 为基础
- 面向对象:
class(包括构造函数和析构函数),封装、继承、多态、虚函数(动态绑定) - 模板:泛型编程。神器
- STL:容器(
array、vector、list等顺序容器,map、set等关联容器)、迭代器、算法、函数对象(仿函数)。
条款 02:尽量以 const, enum, inline 替换 #define
如下面这样一个宏定义:
1
所使用的宏名称可能并未进入记号表,因为宏在预处理阶段会被替换掉,应该用常量替换宏:
1
const double AspectRatio = 1.653
对浮点常量(float point constant)而言,使用常量可能比使用
#define导致较小量的码,因为预处理器会将代码中所有的ASPECT_RATIO替换为1.653,导致目标码(object code)出现多份1.653,若改用常量AspectRatio则不会出现这种问题。下面的
authorName是一个常指针,这个指针指向一个char型常量:1
const char *const authorName = "Scott Meyers";
阅读技巧就是从右向左看。
类的专属常量,即
static const变量:1
2
3
4
5
6class GamePlayer
{
private:
static const int NumTurns = 5; // 类内专属常量的声明式
int scores[NumTurns]; // 使用类内专属常量指定数组维度
}如果类的某个成员变量是
static const的整数型(int、char、bool),且不会执行取其地址的操作,则可以在只声明而未提供定义的情况使用它,否则需要在源文件而非头文件中对其进行定义,且不能在构造函数初始值列表中进行初始化:1
const int GamePlayer::NumTurns;
NumTurns已在声明时获得初值,所以在定义时不可以再设初值。若编译器不支持在类的static成员声明时为其给定初值,或该static成员不是整数型,则可以在定义时给定其初值。无法通过宏来创建类的专属常量,因为宏不重视作用域,一旦宏被定义,它就在其后的编译过程中有效(除非在某处被
#undef),这意味着#define不仅不能用来定义类的专属常量,也不提供任何封装性,意即没有所谓的private #define私有宏。代码在编译期间,数组的维度必须是已知的。
“the enum hack” 补偿,理论基础是一个枚举类型的值可以当作
int来使用:1
2
3
4
5
6
7
8
9
10class GamePlayer
{
private:
enum
{
NumTurns = 5
};
int scores[NumTurns];
}取一个
const的地址合法,取一个enum的地址非法,取一个#define的地址通常也不合法。如果你不想让别人获得一个指针或引用指向你的某个整数常量,enum可以实现。“enum hack” 是模板元编程(template metaprogramming)的基础技术。
宏函数看起来像函数,但不会招致函数调用(function call)的额外开销,因此效率更高。模板内联函数具有宏函数的效率,是更好的选择:
1
2
3
4
5template <typename T>
inline void callWithMax(const T &a, const T &b)
{
f(a > b ? a : b);
}两点结论:
- 对于单纯常量,最好以
const对象或enums替换#define - 对于形似函数的宏(macros),最好改用
inline函数替换#define
- 对于单纯常量,最好以
条款 03:尽可能使用 const
const与指针一起出现时应注意区分,从右向左读即可:1
2
3
4
5char greeting[] = "Hello";
char *p = greeting; // non-const 指针,non-const 数据
const char *p = greeting; // non-const 指针,const 数据(只是说明不能通过 p 修改所指向的数据)
char *const p = greeting; // const 指针,non-const 数据
const char *const p = greeting; // const 指针,const 数据(只是说明不能通过 p 修改所指向的数据)以下两种写法等价,
pw均表示一个指向Widget型常量的指针。更习惯前者的写法:1
2void f1(const Widget *pw);
void f2(Widget const *pw);迭代器的作用类似指针,
const_iterator表示常迭代器,意即迭代器本身的数值不可改变,但迭代器所指向的数据可以改变,类似于常指针。const作用于函数时,可用于修饰函数返回值、函数参数、函数本身(如果是成员函数)。关于修饰返回值,观察下面对*进行重载的示例:1
2
3
4
5
6class Rational
{
// do something
};
const Rational operator*(const Rational &lhs, const Rational &rhs);*的返回值使用const进行了修饰,所以像下面误把=当作==来使用的情况就不会在程序编译阶段通过,因为你尝试为不可修改的值进行赋值:1
if (a * b = c) // 本来是想判断 a * b 的结果与 c 是否相等
当类的成员函数被
const修饰时,成员函数的this指针由T *const转换为const T *const。类的const成员函数需要说明以下两点:- 某个类的
const实例只能调用其const成员函数,不能调用其普通成员函数 - 类的
const成员函数不能修改一般的数据成员,除非数据成员被mutable或static修饰
观察下面的示例,类
demo_03的声明如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class demo_03
{
public:
demo_03();
~demo_03();
void func_const(void) const;
void func_normal(void);
public:
static int data1;
const int data2;
mutable int data3;
int data4;
};定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
int demo_03::data1 = 1;
demo_03::demo_03()
: data2(2),
data3(3),
data4(4)
{
}
demo_03::~demo_03()
{
}
void demo_03::func_const(void) const
{
data1 = 11; // 正确,data1 被 static 修饰
data2 = 22; // 错误,data2 被 const 修饰,不可重新赋值
data3 = 33; // 正确,data3 被 mutable 修饰
data4 = 44; // 错误,const 成员函数不能修改一般的数据成员
}
void demo_03::func_normal(void)
{
data1 = 111; // 正确,一般成员函数可以修改非 const 成员的值
data2 = 222; // 错误,data2 被 const 修饰,不可重新赋值
data3 = 333; // 正确,一般成员函数可以修改非 const 成员的值
data4 = 444; // 正确,一般成员函数可以修改非 const 成员的值
}当
const成员函数尝试修改非mutable或static的数据成员时,编译器会提示你表达式必须是可修改的左值:![const 成员函数只能修改 mutable 或 static 的数据成员]()
我们尝试对
demo_03的一个const实例调用一般方法func_normal:1
2
3
4
5
6
7
8
9
int main()
{
const demo_03 instance;
instance.func_normal();
return 0;
}编译器会提示实例与所调用成员函数的类型限定符不兼容:
![类的 const 实例尝试调用一般成员函数]()
- 某个类的
类的两个成员函数如果只是常量性(constness)不同,可以被重载,观察下面的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class TextBlock
{
public:
const char &operator[](std::size_t position) const
{
// do something else
return text[position];
}
char &operator[](std::size_t position)
{
// do something else
return text[position];
}
private:
std::string text;
};
void print(const TextBlock &ctb)
{
std::cout << ctb[0]; // 调用 const TextBlock::operator[]
}operator[]返回的若是char,则返回值只是text[position]的一个临时副本,对其赋值不合法。当
const和non-const成员函数有着实质等价的实现时,令non-const版本调用const版本可避免代码重复:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class TextBlock
{
public:
const char &operator[](std::size_t position) const
{
// do something else
return text[position];
}
char &operator[](std::size_t position)
{
// do something else
return text[position];
}
private:
std::string text;
};分两步进行:
- 通过
static_cast为*this加上const属性,接下来就会调用重载函数的const版本 - 通过
const_cast移除const重载函数返回值中的const属性
- 通过


条款 04:确定对象被使用前已先被初始化
变量的赋值和初始化是不同的,类的成员初始化过程在构造函数函数体执行前就已完成。
构造函数初始值列表效率更高,即使成员变量是内置类型(此时初始化和赋值成本相同),也最好使用构造函数初始值列表对其进行初始化,因为对于
const成员或引用成员,只能进行初始化,而不能进行赋值。C++ 的成员初始化次序:
- 基类早于派生类被初始化
- 类的成员变量按照其声明次序进行初始化,与其在构造函数初始值列表中的次序无关,所以成员的构造函数初始值列表次序应尽量与声明次序相同
函数内的
static对象称为local static对象(因为它们对函数而言是local),其它static对象称为non-local static对象。函数结束时static对象会被自动销毁,也就是它们的析构函数会在main()结束时被自动调用。C++ 对“定义于不同的编译单元内的
non-local static对象”的初始化相对次序无明确定义。C++ 保证,函数内的local static对象会在“该函数被调用期间” “首次遇上该对象之定义式”时被初始化,这引出了经典的 Meyers 形式的 Singleton 模式实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class ParamsManager
{
private:
ParamsManager(); // 通过将构造函数声明为 private,可以阻止用户私自创建实例
public:
~ParamsManager();
public:
static ParamsManager &GetInstance(void) // 用户只能通过这个 static 方法获取唯一实例
{
static ParamsManager instance;
return instance;
}
};使用 Singleton 模式进行参数管理是个不错的选择,博主在某项目某功能组件的配置参数管理及车身参数管理上使用了类似实现,该实现在 C++11 及以后的标准中是线程安全的。
任何一种
non-const static对象,无论是local还是non-local,在多线程环境下“等待某事放生”都会有麻烦。处理这个麻烦的一种做法是:在程序的单线程启动阶段手工调用所有reference-returning函数,这可消除与初始化有关的“竞速形式(race conditions)”。
2 构造/析构/赋值运算
条款 05:了解 C++ 默默编写并调用哪些函数
如果类中没有得话,编译器会自动声明编译器版本的缺省构造函数、拷贝构造函数、拷贝赋值运算符和析构函数,所有这些函数都是
public和inline。假如写下如下代码:1
class Empty {};
那它和下面的代码是等同的:
1
2
3
4
5
6
7
8class Empty
{
publi
Empty() {} // 缺省构造函数
Empty(const Empty &rhs) {} // 拷贝构造函数
~Empty() {} // 析构函数
Empty &operator=(const Empty &rhs) {} // 拷贝赋值运算符
};这些成员函数只有被调用时才会被编译器创建出来。编译器创建的析构函数是个
non-virtual,除非这个的类的基类自身声明有virtual析构函数(这种情况下这个函数的虚属性virtualness主要来自基类)。编译器创建的拷贝构造函数和拷贝赋值运算符只是单纯地将来源对象的每一个non-static成员变量拷贝到目标对象。出现以下三种情况,编译器不会生成编译器版本的拷贝赋值运算符,而需要用户自行定义:
- 类内含有引用成员
- 类内含有
const成员 - 类的基类的拷贝赋值运算符被声明为
private
条款 06:若不想使用编译器自动生成的函数,就该明确拒绝
通过将类的成员函数声明为
private,并且不给出具体实现,可以达到阻止某些行为的目的,观察下面的示例:1
2
3
4
5
6
7
8
9
10class HomeForSale
{
public:
HomeForSale();
~HomeForSale();
private:
HomeForSale(const HomeForSale &);
HomeForSale &operator=(const HomeForSale &);
};有两点需要说明:
- 通过将拷贝构造函数和拷贝赋值运算符声明为
private,编译器可以阻止对HomeForSale类的拷贝构造及其实例的拷贝赋值 - 通过不给出拷贝构造函数和拷贝赋值运算符的具体实现,链接器可以阻止类的成员函数和友元(
friend)函数对它们的相关调用,因为链接器找不到对象文件中的相应符号(Symbol)
将链接期的错误移至编译期是可以实现的,只需要创建一个基类,在基类中声明
private的拷贝构造函数和拷贝赋值运算符,并让HomeForSale继承它即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Uncopyable
{
protected:
Uncopyable() {}
~Uncopyable() {}
private:
Uncopyable(const Uncopyable &);
Uncopyable &operator=(const Uncopyable &);
};
class HomeForSale : private Uncopyable
{
// do something
};其原理在于,当尝试拷贝构造或拷贝赋值
HomeForSale的实例时,编译器首先试图拷贝构造或拷贝赋值基类(Uncopyable)部分,由于Uncopyable的拷贝构造函数和拷贝赋值运算符被声明为private,导致派生类无权访问,基类部分无法拷贝构造或拷贝赋值,最终导致编译器不会为派生类生成合成的拷贝构造函数和拷贝赋值运算符。也可以使用
Boost库中的noncopyable类。如上文所述,在配置参数管理类ParamsManager的单例模式实现中,为防止用户私自尝试对其进行实例化,将构造函数声明为private。- 通过将拷贝构造函数和拷贝赋值运算符声明为
条款 07:为多态基类声明 virtual 析构函数
该条款与《C++ Primer》第五版第 15.7.1 小节“虚析构函数”相对应。
工厂(factory)函数返回指向派生类对象的基类指针。
如果一个基类指针指向派生类对象,而基类中的析构函数是
non-virtual的,则在delete这个基类指针后,由于无法多态地调用派生类的析构函数,会导致派生类对象中的派生类部分无法销毁,从而造成内存泄漏。带有
virtual函数的class,其数据成员隐含一个 vptr(virtual table pointer,虚表指针),vptr 指向一个由函数指针构成的数组,称为 vtbl(virtual table,虚函数表)。当基类的指针或引用绑定到派生类对象上,并通过该指针或引用调用虚函数时,实际执行的虚函数版本由 vptr 和 vtbl 决定。STL 中的标准容器的析构函数都是
non-virtual的,因此不应该继承它们。可以将类的析构函数定位为
pure virtual(纯虚)的,带有纯虚函致的类是抽象(abstract)的,不可实例化(instantiated):1
2
3
4
5class AMOV
{
public:
virtual ~AMOV() = 0; // 声明纯虚析构函数
};此处的纯虚析构函数的定义是必不可少的,否则链接器会报找不到对应的析构函数符号(Symbol):
1
AMOV::~AMOV() {} // 纯虚析构函数的定义
析构函数的调用是自底向上的,即派生类的析构函数先于基类析构函数被调用。
一个类的析构函数被声明为
virtual应该满足两个前提条件:- 该类会作为基类被继承
- 该类会表现多态特性(拥有至少一个虚函数)
任一条件不满足,类的析构函数都不应是虚函数,所以最佳实践是:如果类中包含虚函数,则该类的析构函数也应该是虚函数。
条款 08:别让异常逃离析构函数
两个异常同时存在的情况下,程序一般会结束执行或发生不明确行为。
可以使用
std::abort()直接终止程序运行,不进行任何资源释放工作。如果某个操作可能在失败时抛出异常,而又必须处理该异常,则该异常必须来自析构函数意外的函数。
析构函数不应抛出异常,若析构函数中某些操作可能产生异常,则析构函数应吞下它们或结束程序。
条款 09:绝不在构造和析构过程中调用 virtual 函数
在构造派生类对象时,对象中的基类成员会先于派生类自己的成员被构造,因此在构造基类成员时,派生类成员尚未初始化,此时的对象是一个基类对象,
virtual函数调用会被编译器解析至基类类型,而不会呈现出想象中的多态特性。一旦派生类析构函数开始执行,派生类对象中的派生类成员变量便呈现未定义状态,进入基类析构函数后,对象彻底退化为基类对象。
pure virtual函数被调用时,大多数执行系统会终止程序(通常会对此结果发出一个信息)。在构造和析构期间不要调用
virtual函数,因为这类调用不会下降至派生类(比起当前执行构造函数和析构函数的那层)。
条款 10:令 operator= 返回一个 reference to *this
连锁赋值:
1
2int x, y, z;
x = y = z = 15;赋值采用右结合律,因此上述上述赋值语句等同于:
1
x = (y = (z = 15));
15 先被赋值给
z,然后更新过的z被赋值给y,最后更新过的y被赋值给x。为实现连锁赋值,赋值操作符必须返回一个引用指向操作符的左侧实参,自定义的类都应该遵守这条约定:
1
2
3
4
5
6
7
8
9class Widget
{
public:
Widget &operator=(const Widget &rhs) // 返回类型是个引用
{
// do something
return *this; // 返回左侧对象
}
};
条款 11:在 operator= 中处理“自我赋值”
通过“证同测试(identity test)”检验“自我赋值”的安全性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class BitMap
{
// do something
};
class Widget
{
public:
Widget &operator=(const Widget &rhs)
{
if (this == &rhs) // 证同测试(identity test)
return *this;
delete pb;
pb = new BitMap(*rhs.pb);
return *this;
}
private:
BitMap *pb;
};证同测试虽然检验了自我赋值的安全性,但不具备“异常安全性”,因为执行
pb = new BitMap(*rhs.pb);时可能产生异常,此时pb是个野值。如果
operator=具备异常安全性,那它往往也具备自我赋值安全性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class BitMap
{
// do something
};
class Widget
{
public:
Widget &operator=(const Widget &rhs)
{
BitMap *pOrig = pb;
pb = new BitMap(*rhs.pb);
delete pOrig;
return *this;
}
private:
BitMap *pb;
};通过 copy and swap 技术实现的
operator=兼具异常安全性与自我赋值安全性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class BitMap
{
// do something
};
class Widget
{
public:
void swap(Widget &rhs); // 交换 *this 和 rhs 的数据
Widget &operator=(const Widget &rhs)
{
Widget temp(rhs); // 拷贝构造 rhs 的副本
swap(temp); // 交换 *this 和 rhs 的副本
return *this;
}
private:
BitMap *pb;
};
条款 12:复制对象时勿忘其每一个成分
拷贝构造函数和拷贝赋值运算符我们统称为 copying 函数,编译器会在必要的时候为我们的类创建 copying 函数。
如果为类添加一个成员变量,必须修改 copying 函数及其它的构造函数,如果忘记,编译器一般不会提醒。
自定义派生类的拷贝构造函数或拷贝赋值运算符时,应显示地调用基类相应的拷贝构造函数或拷贝赋值运算符,目的是拷贝构造或拷贝赋值派生类对象时,对象中的基类部分也能进行相应地拷贝构造或拷贝赋值。
拷贝构造函数和拷贝赋值运算符不应调用彼此,若两者间有重复代码,可新建第三方成员函数将重复代码进行封装,以供两者调用。
3 资源管理
条款 13:以对象管理资源
假如有一个基类
Investment:1
2
3class Investment // 基类
{
};Investment有若干派生类,我们通过工厂函数createInvestment可以获得动态分配的派生类对象指针:1
Investment *createInvestment(); // 工厂函数,内部返回动态分配的派生类对象指针
我们 asda 使用函数
f管理createInvestment返回的派生类对象指针:1
2
3
4
5
6
7
8void f()
{
Investment *pInv = createInvestment(); // 调用工厂函数
// do something
delete pInv; // 释放 pInv 所指对象
}三种情况下
f可能无法删除createInvestment返回的派生类对象指针,导致资源释放失败:- 执行
delete pInv;语句前发生了过早的return语句 - 对
createInvestment的使用及delete动作位于循环体内,该循环由于某个continue或goto语句过早退出 - 执行
delete pInv;语句前发生了异常
为保证
createInvestment返回的资源总是能够被释放,需要将其返回的资源通过对象进行管理,当控制流离开f后,对象的析构函数会自动被调用以释放资源。- 执行
许多资源被动态配于
heap内而后被用于单一区块或函数,它们应该在控制流离开那个区块或函数时被释放,可以使用auto_ptr智能指针(auto_ptr在 C++11 标准中已被弃用,可用新标准中的unique_ptr独占智能指针替代)实现,auto_ptr的析构函数自动对其所指对象调用delete:1
2
3
4
5
6void f()
{
std::auto_ptr<Investment> pInv(createInvestment()); // 通过工厂函数返回的派生类指针初 始化 auto_ptr
// do something
} // 利用 auto_ptr 的析构函数自动释放 pInv 所指对象“以对象管理资源”蕴含两个关键想法:
- 获得资源后立刻放进管理对象(managing object)内。 “以对象管理资源”的观念被称为“资源取得时机便是初始化时机”(Resource Acquisition Is Initialization,RAII),RAII 意味着资源在获得的同时会被放进资源管理对象:初始化或赋值资源管理对象
- 管理对象(managing object)运用析构函数确保资源被释放。 不论控制流如何离开区块,一旦资源被销毁(例如当对象离开作用域)其析构函数自然会被自动调用以释放资源。若资源释放动作可能抛出异常,可参考条款 8
由于
auto_ptr被销毁时会自动删除所指对象,所以不应让多个auto_ptr同时指向同一个对象。若通过拷贝构造函数或拷贝赋值运算符拷贝auto_ptr,被拷贝的指针将变为nullptr,拷贝得到的新的auto_ptr将独占资源。C++11 新标准中,以对象管理资源时,应使用“引用计数型智能指针”(reference-counting smart pointer,RCSP)替代
auto_ptr。RCSP 持续追踪共有多少对象指向资源,并在没有对象指向资源时自动删除资源。RCSP 的行为类似垃圾回收(garbage collection),不同的是 RCSP 无法打破环状引用(cycle of references,例如两个其实已经没被使用的对象彼此互指,因而好像还处在“被使用”状态),共享智能指针shared_ptr就是典型的 RCSP:1
2
3
4
5
6void f()
{
std::shared_ptr<Investment> pInv(createInvestment()); // 通过工厂函数返回的派生类指针 初始化 shared_ptr
// do something
} // 利用 shared_ptr 的析构函数自动释放 pInv 所指对象auto_ptr和shared_ptr在其析构函数内调用的都是delete操作,而非delete[],因此在管理动态分配的数组时不应像上面那样仅使用auto_ptr或shared_ptr:1
2std::auto_ptr<std::string> aps(new std::string[10]); // 释放 new 出来的数组时应使用 delete[]
std::shared_ptr<int> spi(new int[1024]); // 同上标准 C++ 中没有针对动态分配的数组而设计的类似
auto_ptr和shared_ptr的内容,类似的可参考 Boost 库中的 boost::scoped_array 和 boost::shared_array(在新版的 Boost 库中已弃用)。总结:为防止资源泄漏,应使用 RAII 对象对资源进行管理,RAII 对象在构造函数中获得资源并在析构函数中释放资源,
shared_ptr常被用于实现 RAII 对象
条款 14:在资源管理类中小心 copying 行为
假设我们使用 C API 函数处理类型为
Mutex的互斥器对象(mutex objects),有lock和unlock两函数可用:1
2void lock(Mutex *pm); // 锁定 pm 所指的互斥器
void unlock(Mutex *pm); // 将互斥器解除锁定为确保加锁的
Mutex能够不忘解锁,我们使用 RAII 对象对其进行管理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Lock
{
public:
Lock(Mutex *pm)
: mutexPtr(pm)
{
lock(mutexPtr); // RAII 获得资源:锁住 Mutex 指针所指的互斥器
}
~Lock()
{
unlock(mutexPtr); // RAII 释放资源:解锁 Mutex 指针所指的互斥器
}
private:
Mutex *mutexPtr;
};用户可以像下面这样通过
Lock管理Mutex:1
2
3
4
5Mutex m; // 定义互斥器
{ // 使用 {} 限定作用域
Lock ml(&m); // 在限定作用域内创建用于管理 Mutex 的 RAII 对象
} // 自动调用 ml 的析构函数,释放 m对于 RAII 对象的复制,通常有以下几种处理手段:
禁止复制。 如果复制动作对 RAII 类不合理,应该参照条款 6 的做法禁止 RAII 类内部的拷贝构造函数和拷贝赋值运算符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Lock : private Uncopyable // 禁止拷贝构造或拷贝赋值 RAII 对象
{
public:
Lock(Mutex *pm)
: mutexPtr(pm)
{
lock(mutexPtr); // RAII 获得资源:锁住 Mutex 指针所指的互斥器
}
~Lock()
{
unlock(mutexPtr); // RAII 释放资源:解锁 Mutex 指针所指的互斥器
}
private:
Mutex *mutexPtr;
};对底层资源进行“引用计数”(reference-count)。 有时我们希望保有资源,直到它的最后一个使用者(某对象)被销毁,此种情况下复制 RAII 对象时,应将该资源的“被引用数”递增,类似于共享智能指针
shared_ptr。假如我们为上面的Lock类加入引用计数的功能,可以将互斥器指针mutexPtr的类型由Mutex *改为shared_ptr<Mutex>,然而这里存在一个问题,shared_ptr的缺省行为是“当引用次数为 0 时删除其所指物”,而我们想要的动作是当互斥器对象的引用计数为 0 时对其进行解锁而非删除,可以通过指定shared_ptr的“删除器”(deleter)来解决这个问题。deleter是一个函数或函数对象(function object),当引用计数为 0 时便被调用,deleter对shared_ptr构造函数而言是可有可无的第二参数:1
2
3
4
5
6
7
8
9
10
11
12class Lock
{
public:
explicit Lock(Mutex *pm) // 以某个 Mutex 初始化 shared_ptr
: mutexPtr(pm, unlock) // 并以 unlock 函数作为删除器
{
lock(mutexPtr.get()); // get 方法(条款 15 中会提到)返回 shared_ptr 中保存的指针
}
private:
shared_ptr<Mutex> mutexPtr; // 使用 shared_ptr 替换 raw pointer
};可以发现,上述代码并未声明析构函数,因为类的析构函数(无论是编译器生成的,或用户自定义的)会自动调用类内
non-static成员变量(本例中为mutexPtr)的析构函数,而mutexPtr的析构函数会在其所管理的互斥器对象的引用计数为 0 时自动调用shared_ptr的删除器(本例中为unlock函数),因而不再需要显式地在Lock类的析构函数中进行资源释放。复制底部资源。 复制资源管理对象时,进行的是“深拷贝”。
转移底部资源的拥有权。 某些场合下希望任何时刻只有一个 RAII 对象指向某个原始资源(raw resource),即使 RAII 对象被复制依然如此,此时资源的拥有权会从被复制的 RAII 对象转移到目标 RAII 对象,此时需要使用的是独占智能指针
unique_ptr。
总结:复制 RAII 对象必须一并复制它所管理的资源,所以资源的
copying行为决定 RAII 对象的copying行为。常见的 RAII classcopying行为是:抑制copying和对所管理的资源进行引用计数(reference counting)。
条款 15:在资源管理类中提供对原始资源的访问
- RAII 类应该提供访问其所管理的原始资源的方法,例如条款 14 中提到的
shared_ptr中的get方法。
条款 16:成对使用 new 和 delete 时要采用相同的形式
错误代码范例:
1
2
3std::string *stringArray = new std::string[100];
// do something
delete stringArray; // 错误上述代码最后执行的
delete动作将无法正确释放申请的动态内存。delete最大的问题在于:即将被释放的内存里究竟存有多少对象。这决定了最终释放内存时会有多少析构函数被调用。单一对象的内存布局一般不同于数组的内存布局,数组所占用的内存通常还包括“数组大小”的记录,以便delete知道需要调用多少次析构函数,单一对象的内存则没有这笔记录。如果使用
delete时加上中括号,delete便认定指针指向一个数组,否则它认定指针指向一个单一对象,改正后的代码:1
2
3std::string *stringArray = new std::string[100];
// do something
delete[] stringArray; // 正确一个值得小心的例子是当对数组形式作
typedef动作,并进行动态内存分配后,通过delete释放内存时也不应忘记中括号:1
2
3
4
5
6
7typedef std::string AddressLines[4];
std::string *pal = new AddressLines; // 注意,"new AddressLines" 返回一个 string *,
// 如同 "new string[4]" 一样
delete pal; // 错误
delete[] pal; // 正确为避免错误,尽量不要对数组形式作
typedef动作。总结:
new内存时如果使用了[],delete时也需要使用[];new内存时如果没使用[],delete时也不能使用[]。
条款 17:以独立语句将 newed 对象置入智能指针
假设我们有下面两个函数声明:
1
2int priority();
void processWidget(std::shared_ptr<Widget> pw, int priority);则下面的函数调用无法通过编译,因为
shared_ptr的构造函数是explicit的,无法进行隐式类型转换:1
processWidget(new Widget, priority());
改成下面这样显示构造出一个
shared_ptr<Widget>是可以通过编译的:1
processWidget(std::shared_ptr<Widget>(new Widget), priority());
但上述这种写法在实际执行时有可能造成内存泄漏,下面进行原因分析。
在具体执行
processWidget函数体内的代码前,需要计算实参,第一实参的计算包含两个步骤:1)执行
new Widget表达式进行内存分配
2)使用内存分配得到的指针构造出一个shared_ptr<Widget>对象而且内存分配的过程一定先于
shared_ptr<Widget>的构造过程被执行。第二实参只是单纯对
priority()函数的调用,但这个函数调用与第一实参计算过程中的两个步骤的相对执行顺序是不确定的(编译优化),三个步骤有可能是按照下面的顺序被执行的:1)执行
new Widget表达式进行内存分配
2)调用priority()
3)使用内存分配得到的指针构造出一个shared_ptr<Widget>对象如果对
priority()的调用出现异常,则new Widget返回的指针将会丢失,因为它最终未被放入shared_ptr中进行管理。意即,在对processWidget的调用过程中可能引发内存泄漏,因为在“资源被创建(经由new Widget)”和“资源被转换为资源管理对象”两个时间点之间可能发生异常干扰。为避免该问题,应使用分离语句:将内存申请与
shared_ptr构造这两个步骤写为单独的语句,最后将智能指针传入processWidget。代码如下:1
2std::shared_ptr<Widget> pw(new Widget); // 在独立语句内以智能指针存储 newed 所得的对象
processWidget(pw, priority()); // processWidget 调用时 pw 已完成构造上面这种写法之所以是内存安全的是因为,编译器只可能对某条语句内的动作进行重排,但不可能对跨语句的动作进行重排。因此上面这种写法对应的语句执行顺序是:
1)执行
new Widget表达式进行内存分配
2)使用内存分配得到的指针构造出一个shared_ptr<Widget>对象
3)调用priority()总结:在独立语句内将
newed对象存储于智能指针内,否则有可能发生内存泄漏(申请的内存被智能指针管理起来前发生了异常)。

